

Intermediate
How to Monitor a node
Welcome to our tutorial on how to monitor a node on the Tezos blockchain network. In this tutorial, we will cover the process of monitoring the status and performance of a Tezos node. We will explore the various tools and methods that can be used to monitor a Tezos node, such as the Tezos CLI and various third-party monitoring tools.
By the end of this tutorial, you will have the knowledge and hands-on experience needed to monitor the status and performance of your Tezos node, including metrics such as node uptime, block height, and network connectivity. You will also learn how to troubleshoot and diagnose issues with your node. This tutorial is ideal for developers, researchers, and anyone interested in running and maintaining a Tezos node.
Introduction
Until now, the only tool developers had to monitor the behavior of their Tezos node was to look at the logs, adjust the log verbosity, and reconstruct all relevant information from this stream. But getting more insight into a node’s performance was tedious and difficult. For instance, the number of connected peers, the number of pending operations, or the number of times the validator switched branches, were not easy to observe continuously.
After a few iterations of different methods to gather node information and statistics that could be easily analyzed, we have recently chosen to include metrics within the node. With Octez Metrics it’s simple to get a myriad of statistics about your node — and quite efficiently so. You can also attach a Grafana dashboard to get a visual representation of how your node is performing. And with Grafazos, you can get customized ready-to-use dashboards for monitoring your Tezos node.
What metrics can we monitor ?
There are two types of metrics on an Octez node that can be monitored:
-
hardware metrics
-
node metrics
Here is an exhaustive list of Octez node metrics. Hardware metrics depend on your machine characteristics, but we will focus on performance metrics like the CPU usage, RAM, memory, etc.
Overview of monitoring tools
What is Netdata ?
Netdata is a light and open-source software that collects and exposes hardware metrics of a physical machine, and is capable of collecting fresh data every second. Netdata is a complete tool that provides various graphics visualization (histogram, tables, gauge, points…), alerting + triggering tools, and many other features…
What is Grafana ?
Basically, Grafana is a software that takes JSON in input and makes dashboards that you can display using your browser (the high-level web interface that displays all the metrics). In our case, JSONs are provided by Grafazos.
What is Grafazos ?
Grafazos is a jsonnet library written by Nomadic Labs, which uses itself grafonet-lib, which is a jsonnet library to write Grafana dashboards as code.
What is jsonnet ?
Jsonnet is a programming language that allows to create JSONs easily.
What is Prometheus ?
Prometheus server is a toolkit that scrapes and stores time series data by making requests to the nodes. Basically, prometheus is fed by both netdata and tezos-metrics (which is deprecated and not used), and then, grafana displays the data gathered by prometheus.
Light monitoring of an Octez node with Netdata
Set up the monitoring
Step 1: Install Netdata on your node host
We recommend to look at “Install on Linux with one-line installer” to make a personnalised installation. Else, copy the following command:
wget -O /tmp/netdata-kickstart.sh https://my-netdata.io/kickstart.sh && sh /tmp/netdata-kickstart.sh
Step 2: Add the collector plugin for Octez metrics
This plugin scrapes the metrics of your octez node to display the metrics with Netdata. You have the choice between bash, python or go plugins. The best performing plugin is the plugin coded in go. However, if you want to modify a plugin to your liking, choose the language that suits you best. The plugin must be placed in a specific directory as described below:
Bash plugin:
Create a file named tezosMetrics.chart.sh in /usr/libexec/netdata/charts.d and paste the following bash code into the file.
#!/bin/bash
url=http://127.0.0.1:9091/metrics #Octez metrics' are avaible on port 9091 by default. You can changer the url variable if you haven't the same port.
tezosMetrics_update_every=1
tezosMetrics_priority=1
lastTimestamp=
tezosMetrics_get() {
response=$(curl $url 2>/dev/null)
#With this following command you get all metrics of your node except octez_version{...}
eval "$(echo "$response" | grep -v \# | grep -v octez_version | sed -e 's/[.].*$//g' | sed -e 's/", /_/g'| sed -e 's/{/_/g' | sed -e 's/="/_/g' | sed -e 's/"}//g'| sed -e 's/ /=/g'| sed -e 's/<//g'| sed -e 's/>//g'| sed -e 's/\//_/g')"
#this command allows to catch "octez_version" metric
eval "$(echo "$response" | grep -v \# | grep octez_version | sed -e 's/, / \n/g' | sed -e 's/{/\n/g'| sed -e 's/}//g' | sed -e 's/ 0.*//g' |tail -n 6 |sed -e 's/^/octez_/')"
return 0
}
#The following function is called once at netdata startup to check the availability of metrics
tezosMetrics_check() {
status=$(curl -o /dev/null -s -w "%{http_code}\n" $url)
[ $status -eq 200 ] || return 1
return 0
}
#The following function is called once at netdata startup to create the charts
tezosMetrics_create() {
response=$(curl $url 2>/dev/null)
metrics=$(echo "$response" | grep -v \# | grep -v octez_version | sed -e 's/", /_/g'| sed -e 's/{/_/g' | sed -e 's/="/_/g' | sed -e 's/"}//g'| sed -e 's/[ ].*$//g'| sed -e 's/<//g'| sed -e 's/>//g'| sed -e 's/\//_/g')
#CHART type.id name title units family context charttype priority update_every options plugin module
#DIMENSION id name algorithm multiplier divisor options
#More details here: https://learn.netdata.cloud/docs/agent/collectors/plugins.d
for metric in $metrics #this loop creates the charts and the dimensions of all metrics except octez_version metric (because of its format is a bit different)
do
cat << EOF
CHART tezosMetrics.$metric '' "$metric" "" tezosMetricsFamily tezosMetricsContext line $((tezosMetrics_priority)) $tezosMetrics_update_every '' '' 'tezosMetrics'
DIMENSION $metric absolute 1 1
EOF
done
#The code below creates the chart for octez_version
eval "$(echo "$response" | grep -v \# | grep octez_version | sed -e 's/, / \n/g' | sed -e 's/{/\n/g'| sed -e 's/}//g' | sed -e 's/ 0.*//g' |tail -n 6 |sed -e 's/^/octez_/')"
cat << EOF
CHART tezosMetrics.octez_version '' 'node_version: $octez_version | octez_chain_name: $octez_chain_name | octez_distributed_db_version: $octez_distributed_db_version | octez_p2p_version: $octez_p2p_version | octez_commit_hash: $octez_commit_hash | octez_commit_date: $octez_commit_date' '' tezosMetricsFamily tezosMetricsContext line $((tezosMetrics_priority)) $tezosMetrics_update_every '' '' 'tezosMetrics'
DIMENSION 'octez_version' 'node_version: $octez_version | octez_chain_name: $octez_chain_name | octez_distributed_db_version: $octez_distributed_db_version | octez_p2p_version: $octez_p2p_version | octez_commit_hash: $octez_commit_hash | octez_commit_date: $octez_commit_date' absolute 1 1
EOF
return 0
}
#The following function update the values of the charts
tezosMetrics_update() {
tezosMetrics_get || return 1
for metric in $metrics
do
cat << VALUESOF
BEGIN tezosMetrics.$metric $1
SET $metric = $[$metric]
END
VALUESOF
done
#The code below updates the octez_version metric chart
cat << EOF
BEGIN tezosMetrics.octez_version $1
SET octez_version = 0
END
EOF
return 0
}
Step 3: Open the metrics port of your node
When starting your node, add the –metrics-addr=:9091 option to open a port for the Octez metrics. (By default the port is 9091, but you can arbitrarily choose any other one, at your convenience. Just make sure to change the port in the plugin code accordingly.).
Here is an example, when launching your Tezos node:
octez-node run --rpc-addr 127.0.0.1:8732 --log-output tezos.log --metrics-addr=:9091
Step 4: Restart the Netdata server
Once you’ve gotten the plugin on your machine, restart the Netdata server using:
sudo systemctl restart netdata
Step 5: Open the dashboard
You have in fact two ways to open your dashboard:
-
You can access Netdata’s dashboard by navigating to http://NODE:19999 in your browser (replace NODE by either localhost or the hostname/IP address of a remote node)
-
You can also use Netdata Cloud to create custom dashboards, monitor several nodes, and invite users to watch your dashboard… It’s free of charges and your data are never stored in a remote cloud server, but rather in the local disk of your machines.
We recommend to use Netdata Cloud for a more user-friendly usage. The rest of this tutorial is based on Netdata Cloud.
Step 6: Create a custom dashboard with Netdata Cloud!
Netdata provides a really intuitive tool to create custom dashboards. If you wants more details, read Netdata documentation.
Here is an exhaustive list of Octez node metrics. With Netdata, your node metrics will have this format: “tezosMetrics.name_of_your_metric”.
For instance you can monitor the following relevant metrics:
-
octez_versionto get the chain name, version of your node, the Octez commit date, etc. -
octez_validator_chain_is_bootsrtappedto see if your node is bootstrapped (it returns 1 if the node is bootstrapped, 0 otherwise). -
octez_p2p_connections_outgoingwhich represents the number of outgoing connections. -
octez_validator_chain_last_finished_request_completion_timestampwhich is the timestamp at which the latest request handled by the worker was completed. -
octez_p2p_peers_acceptedis the number of accepted connections. -
octez_p2p_connections_activeis the number of active connections. -
octez_store_invalid_blocksis the number of blocks known to be invalid stored on the disk. -
octez_validator_chain_head_roundis the round (in the consensus protocol) of the current node’s head. -
ocaml_gc_allocated_bytesis the total number of bytes allocated since the program was started. -
octez_mempool_pending_appliedis the number of pending operations in the mempool, waiting to be applied.
You can also monitor relevant hardware data (metrics names may differ depending on your hardware configuration):
-
disk_space._to get the remaining free space on your disks. -
cpu.cpu_freqto get the frequency of each core of your machine. -
system.ramto get the remaining free RAM and it’s overall usage.
Plenty of others metrics are available, depending on your machine and needs.
This is an example of a Demo Dashboard with the following metrics:
-
octez_version -
octez_validator_chain_is_bootstrapped -
Disk Space Usage -
CPU Usage -
RAM Usage -
octez_p2p_connections_active -
octez_p2p_peers_running -
octez_store_last_written_block_size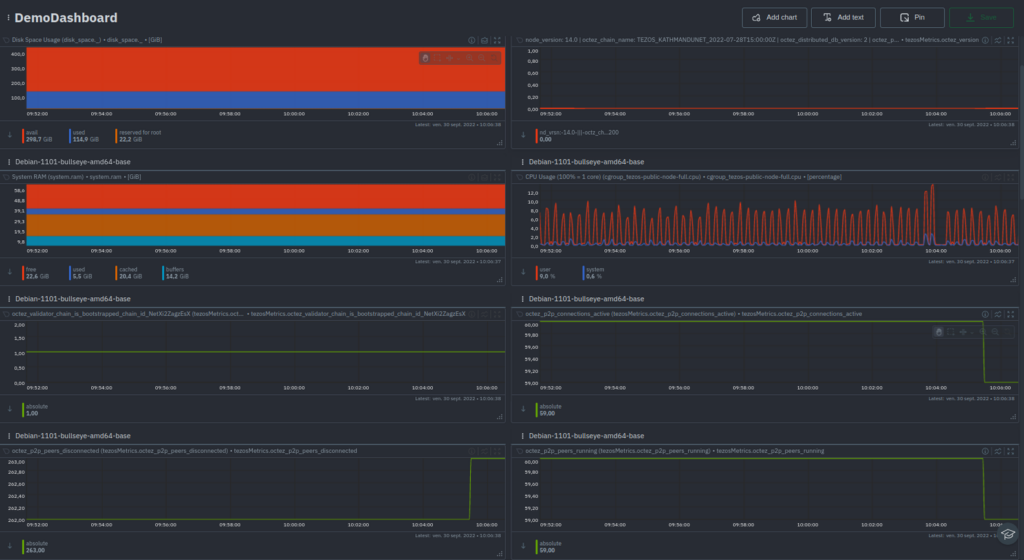
Monitoring several nodes
Step 1. Install Netdata on each of the machines hosting your nodes as described in step 1 of “Set up the monitoring” part.
Step 2. On Netdata Cloud click on the button
Connect Nodes, and follow the instructions.Full monitoring of an Octez node with octez metrics
Here is the global picture of a monitoring system, connecting all these tools together:
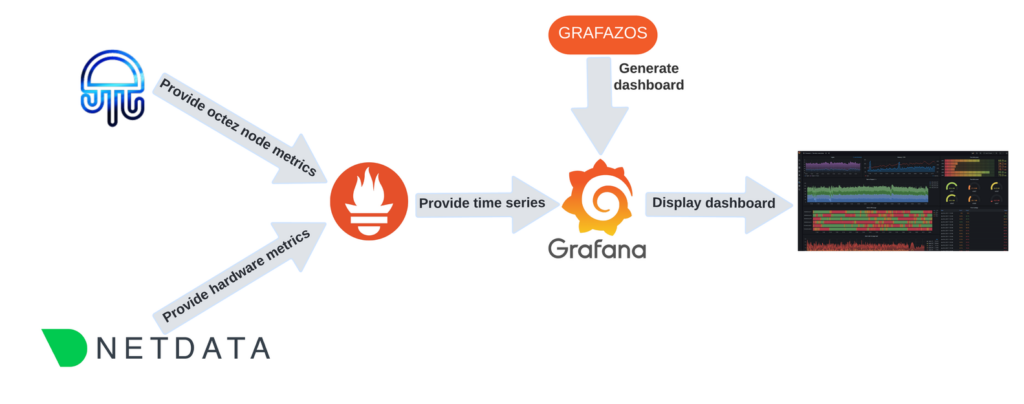
Node metrics
In previous versions of Octez, a separate tool was needed for this task. tezos-metrics exported the metrics which were computed from the result of RPC calls to a running node. However, since the node API changed with each version, it required
tezos-metricsto update alongside it, resulting in as many versions of tezos-metrics as Octez itself. Starting with Octez v14, metrics were integrated into the node and can be exported directly, making it simple to set up. Moreover, as the metrics are now generated by the node itself, no additional RPC calls are needed anymore. This is why the monitoring is now considerably more efficient!Setting up Octez Metrics
To use Octez Metrics, you just start your node with the metrics server enabled. The node integrates a server that registers the implemented metrics and outputs them for each
/metricsHTTP request.When you start your node you add the
--metrics-addroption which takes as a parameter<ADDR:PORT>or<ADDR>or:<PORT>. This option can be used either when starting your node, or in the configuration file (see Node Configuration — Tezos (master branch, 2023/02/13 13:48) documentation ).Your node is now ready to have metrics scraped with requests to the metrics server. For instance, if the node server is configured to expose metrics on port 9932 (the default), then you can scrape the metrics with the request
http://localhost:9932/metrics. The result of the request is the list of the node metrics described as:#HELP metric description #TYPE metric type octez_metric_name{label_name=label_value} x.xTypes of metrics
The available metrics give a full overview of your node, including its characteristics, status, and health. In addition, they can give insight into whether an issue is local to your node, or it is affecting the network at large — or both.
The metric
octez_versiondelivers the node’s main properties through label-value pairs. It provides the node version or the network it is connected to.Other primary metrics you likely want to see are the chain validator1 ones, which describe the status of your node:
octez_validator_chain_is_bootstrappedandoctez_validator_chain_synchronisation_status. A healthy node should always have these values set to 1. You can also see information about the head and requests from the chain validator.There are two other validators, the block validator2 and the peer validator3, which give you insight on how your node is handling the progression of the chain. You can learn more about the validators here
To keep track of pending operations, you can check the
octez_mempoolmetric.You can get a view of your node’s connections with the p2p layer metrics (prefixed with
octez_p2p). These metrics allows you to keep track of the connections, peers and points of your node.The store can also be monitored with metrics on the save-point, checkpoint and caboose level, including the number of invalid blocks stored, the last written block size, and the last store merge time.
Finally, if you use the RPC server of your node, it is likely decisive in the operation of your node. For each RPC called, two metrics are associated:
octez_rpc_calls_sum{endpoint="...";method="..."}andoctez_rpc_calls_count{endpoint="...";method="..."}(with appropriate label values). call_sum is the sum of the execution times, and call_count is the number of executions.Note that the metrics described here are those available with Octez v14–it is likely to evolve with future Octez versions.
Dashboards
While scraping metrics with server requests does give access to node metrics, it is, unfortunately, not enough for useful node monitoring. Since it only gives a single slice into the node’s health, you don’t really see what’s happening over time. Therefore, a more useful way of monitoring your node is to create a time series of metrics.
Indeed, if you liked the poster, why not see the whole movie?
The Prometheus tool is designed for this purpose which collects metric data over time.
In addition, in order to get the most out of your metrics, it should be associated with a visual dashboard. A Grafana dashboard, generated by Grafazos gives a greater view into your node. Once your node is launched, you can provide extracted time series of metrics to Grafana dashboards.
The Grafazos version for Octez v14 provides the following four ready-to-use dashboards:
-
octez-compact: A compact dashboard that gives a brief overview of the various node metrics on a single page. -
octez-basic: A basic dashboard with all the node metrics. -
octez-with-logs: Same as basic but also displays the node’s logs, with Promtail Promtail (for exporting the logs). -
octez-full: A full dashboard with the logs and hardware data. This dashboard should be used with Netdata (for supporting hardware data) in addition to Promtail.
Note that the last two dashboards require the use of additional (though standard) tools for hardware metrics and logs (Netdata, Loki, and Promatail).
Let’s look at the basic dashboard in more detail. The dashboard is divided into several panels. The first one is the node panel, which can be considered the main part of the dashboard. This panel lays out the core information on the node such as its status, characteristics, and statistics on the node’s evolution (head level, validation time, operations, invalid blocks, etc.).
The others panels are specific to different parts of the node:
-
the p2p layer;
-
the workers;
-
the RPC server;
along with a miscellaneous section.
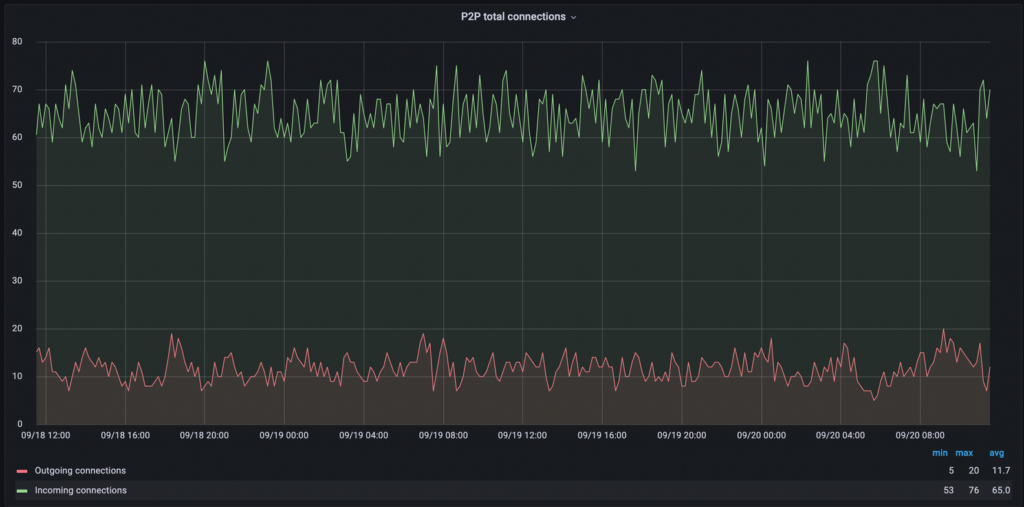
Some metrics are self-explanatory, such as P2P total connections, which shows both the connections your node initiated and the number of connections initiated by peers. Another metric you may want to keep an eye on is Invalid blocks history, which should always be 0 — any other value would indicate something unusual or malicious is going on.
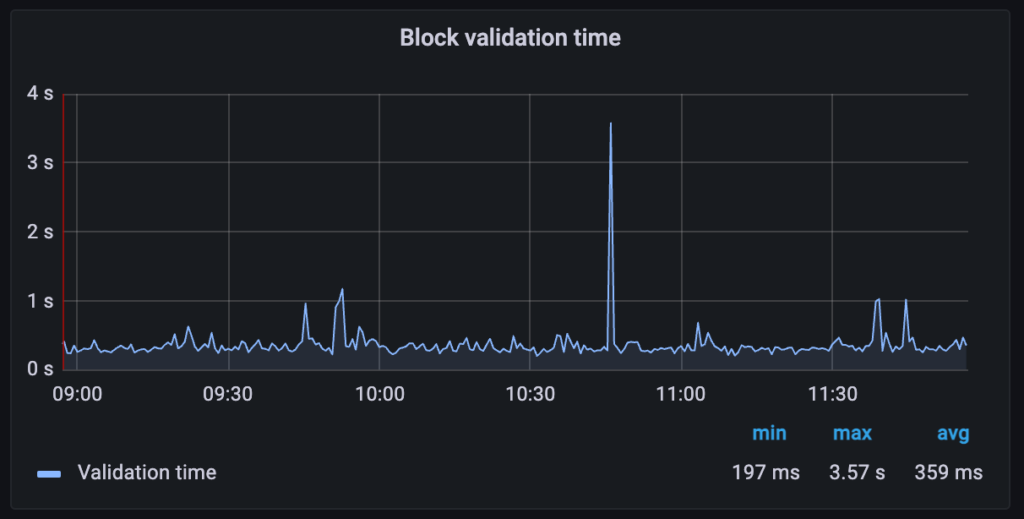
Another useful metric is the Block validation time, which measures the time between when a request is registered in the worker till the worker pops the request and marks it complete. This should generally be under 1 second. If it’s persistently longer, that could indicate trouble too.
Graph 2: Block validation
-
The P2P connections graph will show you immediately if your node is having trouble connecting to peers, or if there’s a drop-off in the number of connections. A healthy node should typically have a few dozen peer connections (depending on how it was configured).
Graph 3: P2P connections

The Peer validator graph shows a number of different metrics including unavailable protocols. An up-to-date, healthy node should see this as a low number. If not it can indicate that your node is running an old version of Octez, or that your node is being fed bad data from peers.
Note again these dashboards are built for Octez v14 and are likely to evolve with the Octez versions.
Working with Grafazos
Grafazos allows you to set different options when generating the ready-to-use dashboards described above. For instance, you can specify the node instance label, which is useful for a dashboard that aims to monitor several nodes.
Furthermore, you can manually explore the metrics from the Prometheus data source with Grafana and design your own dashboards. Or you can also use Grafazos to import ready-to-use dashboards for your node monitoring. You can find the packages stored here. There is a package for each version of Octez.
Grafana is a relatively user-friendly tool, so play with creating a custom one as you like. You may also want to use the “explore” section of Grafana. Grafazos is also particularly useful in automatic deployment of Tezos nodes via provisioning tools such as Puppet or Ansible.